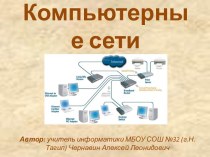
Преимущества компьютерного документа:
Компактное размещение
Легко удалить
Легко размножить
Можно быстро
переслать на большое расстояниеНедостаток:
Прочитать файл можно только
с помощью компьютера