как последовательность разных, иногда и взаимосвязанных, явлений. Еще в
древности люди различными способами описывали эти явления, часто даже не понимая их сущности. Сегодня это описание называется данными. К данным относятся: факты, явления, события, идеи или предметы.
Фиксация данных традиционно происходит через конкретные средства общения - естественного языка или изображений, на конкретном носителе: камне или бумаге. Учитывая тот факт, что естественный язык обладает достаточной гибкостью, данные и их интерпретация (семантика) фиксируются совместно. Например, рассмотрим утверждение "Стоимость билета на электричку 147". Здесь "147" - данное, а "Стоимость билета на электричку" - его семантика.
Очень часто данные и интерпретация разделяются. Например, "Расписание движения поездов" представляется в виде таблицы, в которой в верхней части отдельно от данных будет приведена их интерпретация, а это затрудняет работу с данными и приводит к сложности получения сведения из нижней части таблицы.
Разделение данных и интерпретации становиться еще более ощутимым, когда ЭВМ применяется для ввода и обработки данных. Это происходит потому, ЭВМ может иметь дело только с данными. Большая часть интерпретирующей информации не фиксируются в явной форме (ЭВМ не "понимает", является ли "22.50" стоимостью авиабилета или временем вылета). Почему так происходит?
Существуют как минимум две исторические причины, способствующие тому, что активное использование ЭВМ способствовало тому, что произошло разделение данных и интерпретации:
- ЭВМ не имело достаточных возможностей, чтобы обрабатывать тексты на естественном языке - основном языке интерпретации данных;
высокая стоимость памяти ЭВМ.
Память использовали для того, чтобы хранить сами данные, а интерпретацией занимались непосредственно пользователи. Процесс выглядел следующим образом, интерпретацию данных закладывали в программу, которая "понимала", например, что пятое вводимое значение связано с временем прибытия поезда, а пятое - с временем его убытия. Такая последовательность действий делала программу незаменимой, потому что без интерпретации данные всего лишь совокупность битов на запоминающем устройстве.
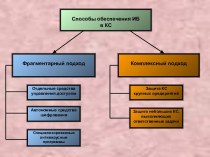
Все серьезные проблемы, которые возникают при введении данных, связаны с тем, что между данными и использующими их программами существует очень жесткая связь.
Как показывает практика, совместное использование одних и тех же данных, приносит массу проблем. Например, очень часто бывает так, что при использовании одной и той же ЭВМ пользователями создаются и используются в программах разные наборы данных, содержащие сходную информацию. Это можно объяснить тем, что пользователь просто не имеет информации о том, что сотрудник, который работает рядом, давно ввел в ЭВМ нужные данные.
Очень удобно при использовании, когда разработчики прикладных программ, размещают нужные им данные в файлах. Надо учитывать, что одинаковые данные в разных приложениях отличаются организацией, то есть обладают разной последовательностью размещения в записи, разные форматы одних и тех же полей и т.п. Поэтому обобщить все данные очень сложно. Это связано с тем, что если один разработчик производит изменение структуры записи файла, то и другой разработчик должен произвести изменения в программах, использующих записи этого файла.
Возврат в
содержание